
This is the story about how a Tweet forced me to put my money where my mouth was and to write a Java parser for The Secret of Monkey Island.
Update 2023-11-16
Elon Musk pretty much ran down Twitter and I don’t want any share in it by providing content. All my Twitter accounts are closed and this includes both Monkey Island Quote Bots. But for over a year now they have found a new home in the fediverse!
Some time around the 2020 holiday season I felt like there was something important missing on Twitter: A bot that tweets “The Secret of Monkey Island” quotes.
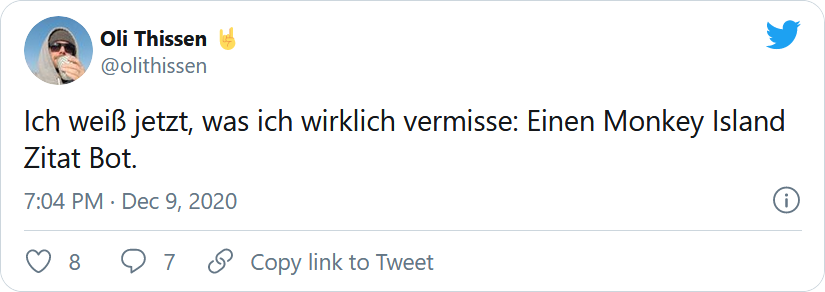
Well, thats obviously a tweet in German
When I started writing this post I was thinking about all the things I wanted to tell you about how to build your own Twitter bot with Node.js, AWS Lambda and Serverless. But then I realized that I just looted other peoples blog posts and that I really didn’t have anything of value to add 🤷♀️
So for the purely technical part of writing a Twitter bot: Here you go
- How I Built a Serverless AWS Lambda Twitter Bot in NodeJS in a Single Day
- Monkey Island Bot (for Mastodon) repo on GitHub

The carribean according to VGA mode 13h
Ok, so where are you going with this?
Bear with me here.
Obviously a Twitter bot tweeting Monkey Island quotes requires Monkey Island quotes. You can get the entire 98.7 GB ScummVM collection over at archive.org. (And you can browse for individual files if downloading 98.7 GB isn’t for you: Link) Don’t ask me about the level of legality in your jurisdiction.
Getting all the quotes or rather “all text strings” from the game files shouldn’t be too hard or so I thought.
So at first I tried a few pragmatic approaches like splitting the entire game file by 0x00 and then checking the results against a dictionary to see if they make any sense.
(Spoiler: They dont’t)
In the end there was only one way to solve this: My own SCUMM parser
SCUMM
The “Script Creation Utility for Maniac Mansion” or SCUMM is an impressive piece of software and while I was cursing my way through the game files I grew more and more impressed: In 1987 Ron Gilbert, Aric Wilmunder and Chip Morningstar wrote a scripting language that would compile to platform-independent bytecode and that would run on a platform-specific interpreter called SPUTM that upon release would be renamed to the game executable.
While your classic The Secret of Monkey Island is probably version 4, the newer VGA/CD-ROM versions are version 5, which is neat because everything you’re going to so see also applies to Monkey Island 2: LeChuck’s Revenge.
Everything from here on is SCUMM v5. I’ll point it out if I’m talking about any other version.
Game Files
Before we proceed to the actual scripts, let’s have a look at the structure of the files.
Monkey Island (and SCUMM games in general) are structured in one index file (like monkey.000) and 1..n data files (like monkey.001).
First of all these files are XORed with a specific value - for whatever reason.
For The Secret of Monkey Island this value is 0x69.
If you want to make sense of them in a hex-editor you will first have to XOR them with this value.
In the SCUMM terminology these files are called archives and consist of chunks. Since archives contain hierarchical data, these chunks come in container chunks and leaf chunks.
A handy tool to see how the files are structured is ScummEX, sadly with v0.1 from 2003 being the latest and with no source code to be found 🙁. As an alternative there is ScummEditor which feels more fluent and has code available on GitHub but is missing a script parser. ScummEX seems stronger with scripts, ScummEditor seems to focus on the graphics and animation part.
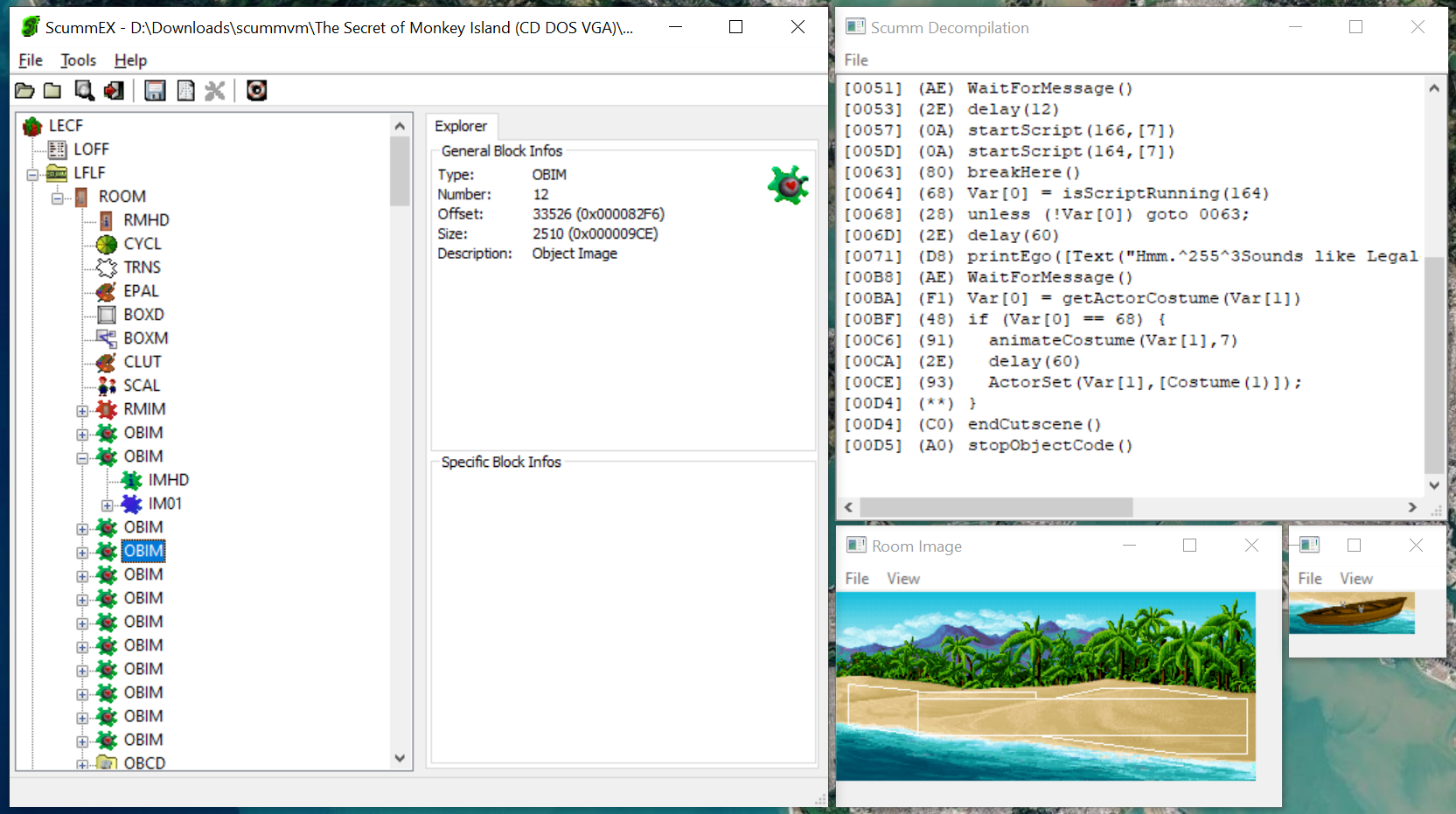
Lots and lots of structured data in ScummEX
All chunks start with a 4 byte chunk tag followed by a 32-bit big-endian integer giving its total length including the tag itself. In this example we have a LFLF chunk of 45946 (B37A16 BE) bytes with a ROOM chunk of 45935 (B37216 BE) bytes as first child item, followed by the room-header RMHD and so on:

The first ROOM we encounter in monkey.001
The entire archive is structured in this way, defining graphics, sprites, animations, costumes, color palettes, walk boxes, sounds and everything else. And scripts of course.
Scripts
SCUMM knows different types of scripts.
- SCRP: Global scripts
- LSCR: Local scripts (multiple per room)
- ENCD: Room entry script (one per room)
- EXCD: Room exit script (one per room)
- OBCD: Object scripts (one per object)
These scripts are represented by the byte-code I mentioned in the SCUMM introduction.
The byte-code knows a total of 101 different opcodes.
opcodes without additional parameters like PrintEgo (Guybrush talking) are represented with a unique byte value like 0xD8.
Others like LessOrEqual are represented by either 0x38 or 0xB8 and WalkActorTo even has eight different codes.
Well, then extracting strings should be easy since every text output is marked with the opcode Print (0x14|0x94) or PrintEgo (0xD8)!

Guybrush reading the Cannibals’ letters to Herman Toothrot
But there is a caveat:
As all opcodes are single bytes and we are looking at a binary file, these bytes can and will appear in other positions.
So every script chunk has to be walked opcode by opcode in order to get to the real Print opcodes.
And this is where the real work begins.
As mentioned above many opcodes (the majority even) are not uniquely represented by a single byte value, and there is a reason for that:
These opcodes are dynamic in lenght as they may take different parameters like variables or constants in form of BYTE or WORD (or worse).
This behavior is controlled by the different characteristics of the opcode.
Let’s have a closer look at the WalkActorTo opcode represented by 0x1E, 0x3E, 0x5E, 0x7E, 0x9E, 0xBE, 0xDE and 0xFE:
hex bin
---- --------
0x1E 00011110
0x3E 00111110
0x5E 01011110
0x7E 01111110
0x9E 10011110
0xBE 10111110
0xDE 11011110
0xFE 11111110
You can see that they all share the last five bits (xxx11110) while the first three vary.
That means we can use bitwise operations to determine if a value belongs to an opcode and which of the three possible flag-bits are set.
The opcode detection can be done with a bitwise AND operation (& in Java and many other languages).
So if we perform 0x5E & 0x1E we will get 0x1E and we know that we have a WalkActorTo opcode.
We’ll need that later.
Likewise we can use 0x80 (10000002), 0x40 (01000002) and 0x20 (00100002) as bitmasks to check for flags:
0x5E & 0x80yields0x00so the flag is not set.0x5E & 0x40yields0x40(or better:not 0x00) so it is set.
But what’s up with these flags?
The flags control how the opcode parameters are read and are bound to the first (0x80), second (0x40) and third (0x20) parameter.
In contrast to SPUTM or ScummVM my parser is not really interested in the parameters content but only in its length to correctly advance the read pointer.
The WalkActorTo opcode has three parameters:
actorwhich can either be a (local) variable or a byte constant (“direct byte”)xandyeach of which can either be (local) variable or a word constant (“direct word”)
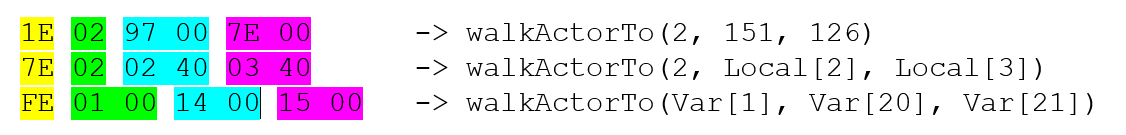
Different variants of the WalkActorTo opcode
For 0x7E and 0xFE, where a bitwise AND 0x80 results to ≠ 0, the first parameter is suddenly interpreted as a variable reference instead of a byte constant.
As you might have guessed, there is another bitwise comparison under the hood to tell script-local and global variables apart.
Now this is still somewhat straight forward, but what about more complex situations?
If you think about the Print opcode there are several more settings to be considered like position, color, alignment and of course the text itself.
This is achieved with sub-opcodes.
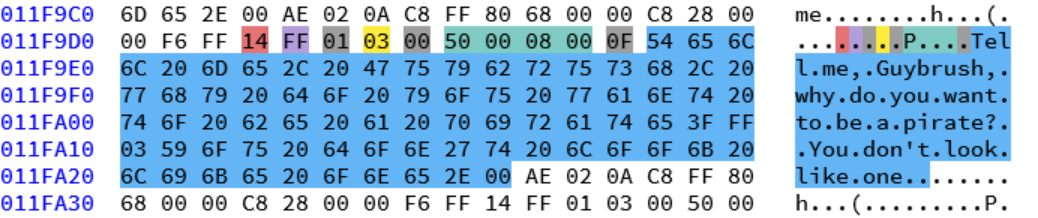
Elaine talking to Guybrush.
In the above example of Elaine talking to Guybrush, the Print opcode is started by 0x14 and set to actor 0xFF (which is a dummy value for a floating text without a specific actor. The actor is usually set to achieve overhead text).
Next up is the first sub-opcode 0x01 to set the font color to palette index 3.
What if for whatever reason the color wasn’t supposed to be a constant but a variable?
Then instead of 0x01 we would have 0x81, setting the bit-flag for the first parameter of the sub-opcode to a variable.
The same goes for the next sub-opcode 0x00 which sets the x and y position of the text to the word constants
(and suddenly they are little endian. Huh!)
Finally the last sub-opcode 0x0F starts the text to print and is simply and old-fashioned terminated by 0x00.
And that’s what I was looking for the entire time!
Ok, so is that it?
Well, yes, sort of. There are some more really ugly things in there that would really break the mold here. Special 24-bit values, resource pointers that behave a lot but not entirely like text strings. And there are certain variables that have special bit flags, forcing the parser to recursively proceed to the referenced variable until said flag is no more set. These were really, REALLY bad, pushing me to the brink of giving up.
But yes, that’s it and that’s what the MonkeyBusiness parser does:
- XOR the archive
- identify and isolate all the script chunks
- run the opcode parser on each one and return all opcodes
- filter and clean up everything that’s dialog text (did I tell you about the dramatic pause control character
0xFF03?) - leave me with my favorite, not so obvious Monkey Island quote: “Chimps? There aren’t any chimps in the Caribbean!”
Thanks
- My script parser heavily lends from the one built by the ScummVM project, especially from the script_v5 interpreter. ScummVM is available on almost all platforms you might think of. Consider leaving them a donation. I did.